Inledning
Öppna data utgör en interaktionsgräns för delning, utbyte och kombination av digitala resurser mellan offentlig sektor, medborgare, företag och idéburna organisationer. För att öppna data skall bli en viktig resurs som kan användas för att skapa samhällsvärde räcker det inte med vilja och målsättning att tillgängliggöra data direkt från interna IT-system. Arbetet måste vägledas av grundläggande designprinciper som möjliggör delning, utbyte och kombinering av data och information utan behov av integration mellan IT-system för enskilda ändamål. En av dessa grundprinciper är att skapande av interoperabilitet för utbyte, vidareutnyttja och kombinera digital resurser.
Interoperability -Relating to systems, especially of computers or telecommunications, that are capable of working together without being specially configured to do so. Källa: The Free Dictionary
Principer om interoperabilitet berör alla aspekter av hantering av data och information för att motverka fragmenterade och vertikala systemlösningar inom en verksamhet. Bristen på interoperabilitet skapar inte bara hinder för att vidareutnyttja digitala resurser internt, det gör det också kostsamt och tidsödande att integrera mot externa resurser. Flera organisationer lever med fragmenterade och vertikala systemlösningar eftersom beslut om anskaffande av IT-system ofta ensidigt fokuserar på lösningar. Därför är det viktigt att offentliga organisationer och myndigheter säkerställer interoperabilitet så att digitala resurser kan vidareutnyttja internt, externt och för olika ändamål och verksamheter.
Genom att förädla, sammanställa och på andra sätt använda information kan olika aktörer skapa nya kommersiella och ideella tjänster och därmed ge förutsättningar för samhället att tillgodogöra sig det värde informationen kan ha när den används för andra ändamål än myndighetens egen verksamhet. – Regeringens digitaliseringsstrategi (N2017/03643/D, sida 22)
Principer som gör det möjligt att vidareutnyttja och kombinera digitala resurser med varandra behöver genomsyra alla systemlösningar i en verksamhet. En central princip för att möjliggöra interoperabilitet är att nyttja öppen källkod. Varför detta är viktigt finns att läsa om på sidan om öppen källkod och standard. För att det ska ske en förändring behövs det en attitydförändring och kunskap om öppen källkods fördelar för de som utformar upphandling och avtal inom offentliga organisationer. Om offentliga medel i större utsträckning investerades i öppen källkod och standarder kan flera organisationer få tillgång till viktig IT-infrastruktur som möjliggör effektivisering genom att digitala resurser kan vidareutnyttjas och kombineras över organisationsgränserna.
Innovationsupphandling och innovationspartnerskap är i sammanhanget viktiga verktyg liksom medveten användning av lösningar av öppen källkod, standarder och testbäddar. – Regeringens digitaliseringsstrategi (N2017/03643/D, sida 25)
Förutom designprinciper behövs det ledarskap inom offentlig sektor med kompetens om vad som krävs för att utveckla IT-infrastruktur och tillgängliggöra digitala resurser som kan vidareutnyttjas för olika ändamål för att införliva digitaliseringens potential.
För de statliga myndigheterna bör behovet av strategisk digital kompetens beaktas vid förordnande av ledamöter i myndighetsstyrelser, nämnder och insynsråd – Regeringens digitaliseringsstrategi (N2017/03643/D, sida 15)
För att göra data ändamålsenlig för fler tillämpningsområden behövs strategier som nyttjas inom hela verksamheten för hur data lagras, hanteras och struktureras. Dessa designprinciper behöver ingå i direktiv som beslutas av ledningen för att visa på betydelsen av att nyttja goda designprinciper och praxis för hantering av data så den kan vidareutnyttjas horisontellt inom offentlig sektor, företag, sociala och idéburna organisationer. Detta innebär att data behöver vara enkel att läsas och tolkas av maskiner, enkel att hitta, lätt att kombinera med annan data genom öppna standarder och format.
Offentlig sektor bör även bli bättre på att återanvända sin egen data, inom och mellan myndigheter, på ett sätt som möjliggör nya tjänster och ökad flexibilitet i kontakten med människor och företag, exempelvis med hjälp av artificiell intelligens. – Regeringens digitaliseringsstrategi (N2017/03643/D, sida 22-23)
Data som strategisk resurs
Som nämndes i inledningen ger öppna data möjligheten att samarbeta över organisationsgränser med andra aktörer för att dela och kombinera digitala resurser. Om öppna data inte hanteras som en strategisk resurs finns det risk att frågan inte prioriteras och arbetet kring att tillhandahålla data styrs av tillfälliga insatser. Om det inte finns nationella målsättningar att tillgängliggöra samhällsviktig data, kan insatser att öppna upp data istället styras av det som är tekniskt enkelt att tillhandahålla eller vara mindre politisk känsligt. Detta kan leda till att den fulla potentialen av digitaliseringen inte infrias och att resurser går förlorade. Därför behövs digitala resurser ses en strategisk viktig resurs oavsett om det skall användas internt eller tillgängliggöras för externa användare. Annars kan detta få stora implikationer, vilket vi såg när Transportstyrelsen outsourcade sin IT-infrastruktur som hanterade samhällsviktig data.
Dataformat och metadata
Beslut om vilka format som skall användas för att tillgängliggöra data behöver insikt och kännedom om vad som är ändamålsenligt för det tilltänkta användningsområdet. Det finns många olika dataformat med olika för och nackdelar, och det finns inget optimalt format som passar för allt. Däremot finns det format som både är maskinläsbara och enkla att läsa för människor som dessutom har utmärkt stöd för metadata, som exempelvis JSON och XML. Båda formaten är öppna och har en hieratisk struktur, det vill säga att data kan kategoriseras i olika nivåer och undergrupper – vilket gör det enkelt för användaren att transformerar mellan formaten beroende på vilket som passar bäst. JSON och XML har stöd för metadataschema vilket möjliggör beskrivning av objekt, datatyper för attribut och validering av möjliga värden. Metadataschema gör livet mycket lättare för utvecklare som vill vidareutnyttja data utan att behöva tolka och gissa vilka datatyper och värden som är rimliga. Länken visar ett exempel på hur ett schema ser ut för ett XML-schema. JSON och XML är anpassningsbara format och utgör grunden för de flesta standarder som används på nätet. Dessutom har de flesta webb och programmeringsmiljöer utmärkt stöd för att hantera och behandla data som tillgängliggörs i JSON och XML.
Metadata är lika viktigt som data om det det skall användas av andra än dig själv eftersom det beskriver för användare vilka egenskaper, struktur och hur det skall tolkas. För att göra en liknelse, föreställ dig att du är intresserad av en bil som står parkerad utanför en bilförsäljare, men som saknar information angående pris, miltal, årtal, bensin/diesel- och annan viktig fakta angående bilens beskaffenhet. Avsaknaden av fakta kring bilens egenskaper kommer antagligen göra att du som spekulant tappar intresse eftersom bilförsäljaren verkar oseriös. En rapport från European Data Portal (2016) visar att endast 26 procent av öppen data i Sverige tillgängliggörs i maskinläsbara format som JSON och XML. Att så mycket data och information tillgängliggörs i format som inte är läsbara av maskiner betyder att mycket tid och resurser går förlorade eftersom användare inte enkelt kan vidareutnyttja, kombinera och länka det men annan data.
Att tillgängliggöra data utan metadata kommer begränsa vidareutnyttjande och möjligheten att kombinera det med annan data. Kommaseparerade filer (CVS) är ett öppet maskinläsbart format, men saknar möjligheten att definiera metadata och lämnar över ansvaret att tyda, transformera och validera data till användaren. Detta gör formatet mindre användbart för användare som behöver kombinera många olika datakällor. Bra metadata definitioner erbjuder alla användare stöd oavsett om man är bekanta med datasetet eller inte. Tabellen visar på vanliga dataformat och stöd för metadata definition.
| Format | Metadata stöd | Beskrivning |
|---|---|---|
| ZIP (komprimerad fil) | Inget | Inget stöd för metadata. |
| CSV (kommaseparerad fil) | Inget | Inget stöd för metadata, första raden kan innehålla namn på kolumn |
| Begränsat | Metadata om skapare och datum. | |
| Kalkylark (Excel) | Begränsat | Metadata om skapare, datum, format och datatyper. För att extrahera metadata behövs specialprogram eller moduler. Metadata är inte en naturlig del och formatet är proprietärt |
| JPG, PNG | Fullgott | Metadata om skapare, datum, licensregler, geografisk plats, samt kamerainställningar med mera |
| JSON, XML | Fulländat | Metadata strukturer för beskrivning av, ägare, datum, tidszoner, komplexa datatyper och validering av tillåtna värden. Formaten innehåller metadataschema för beskrivning av taxonomier som innehåller objekt och hierarkier |
Dataresurser på nätet
WC3 är en medlemsorganisation som driver viktiga öppna standardiseringar och ser till att webben fungerar som den gör idag. Grundaren Tim Berners-Lee skapade första versionen av hypertext standarden 1991 (HTTP och HTML), som möjliggjorde sammanlänkning av text, bilder och video på nätet. W3C och Tim Berners-Lee (TED talk) har varit en förespråkar sedan mitten av 2000-talet av ett paradigmskifte från att publicera text – till att publicera data på nätet. Protokollet som gör detta möjligt är uniform resource identifier (URI) och publicerades i sin nuvarande version (RFC 3986) redan 2005. De flesta är mest bekanta med URL (uniform resource locator) delen av standarden för adresser till webbplatser. Genom att nyttja hela URI standarden blir det möjligt att skapa en unik identifierare (URI) och publicera dataresurser på nätet. URI:er kan användas för att publicera data och information om fysiska och abstrakta resurser på nätet som exempelvis skolor, vägar eller regionindelning. Det är upp till den som publicerar data att säkerställa att (URI) identifierarna är både unika och beständiga över tid, vilket möjliggör förtroende mellan tillhandahållare och användare av data resurser på nätet.
En av fördelarna med URI protokollet är att det redan används idag för att publicera innehåll på webben. Protokollets regler för unika identifierare och dess inbyggda stöd för begreppsmodeller möjliggör beskrivning av komplexa samband och egenskaper som möjliggör interoperabilitet och vidareutnyttjande av data och information med bibehållen betydelse mellan organisationer och över nationsgränser. Stycket nedanför beskriver designprinciper för URI:er och grunden för länkad data, begreppsmodeller och den semantiska webben. W3C som tillhandahåller standarderna är en öppen medlemsorganisation för företag och verksamheter som vill delta i standardiseringsarbetet med någon av de för närvarande 95 standarder som ligger under organisationens paraply.
URI design
Med hjälp av unik identifierare (URI) kan data enklare vidareutnyttjas och länkas med annan data på nätet. URI:er kan användas för att publicera data och information om fysiska och abstrakta resurser på nätet som exempelvis skolor, vägar eller regionindelning. För att referera till resurser behöver identifierare och adresser vara beständiga över tid och vara logiskt strukturerade. Länken nedanför är en URI som beskriver länet Kent syd-ost om London, som är länkat till andra resurser som exempelvis regioner, vägar och geografiska egenskaper för att skala geografisk kontext.
http://data.ordnancesurvey.co.uk/doc/7000000000018210
URI:n för länet Kent följer riktlinjer för hur offentliga organisationer bör publicera dataresurser på nätet i Storbritannien (designing URI sets for the UK public sector). Att tillgängliggöra data och information som resurser på nätet kan vara ett omfattande arbete som bör göras iterativt eftersom det troligen kräver tillpassning och av både arbetssätt och IT-stöd. Därför rekommenderar W3C att börja publicerat data som har stort samhällsvärde och som kan vidareutnyttjas inom offentlig sektor. Att strukturera och publicera resurser med beständiga URI:er är en del av rekommendationen för publicering av länkad data som beskrivs i stycket nedanför.
Länkad data
Innan hypertext (HTML & HTTP) lanserades var inte existerande elektroniska dokument länkade med varandra på ett standardiserat sätt, vilket gjorde det svårt att referera till varandras dokument och skapa sammanhang. I dag står vi inför en liknande problematik med mängder av fristående datakällor på nätet som inte nyttjar standardiserade format och protokoll för att göra data mer användbar och tillgänglig. Precis som dokumenten på internet, behövs data länkas med varandra för att enklare kunna hittas och skapa kontext. Länkad data tillsammans med semantiska modeller, möjliggör att data blir överförbar mellan system, organisationer och landsgränser med bibehållen betydelse.
Länkad data nyttjar samma protokoll som används för att adressera webbsidor på nätet. Uniform Resource Identifier (URI) används för att identifiera unika resurser på nätet. Webbplatser använder oftast bara Uniform Resource Locator (URL) av protokollet för att identifiera unika platser. Styrkan med länkad data är att data kan kopplas ihop med annan data över organisationsgränser genom att använda beprövad teknik som redan är tillgänglig. Att publicera data med unik identifierare (URI) kräver lite mer förberedelse gentemot att publicera HTML-sidor, eftersom unika identifierare (URI) behöver vara kopplade till nycklar som används av interna IT-system. Unika identifierare behöver också skapas utifrån en konvention och process som kan förstås av människor och maskiner, som exempelvis Storbritanniens designriktlinjer för URI:er. Detta är viktigt för att göra URI:erna beständig över tid och möjliggöra vidareutnyttjande av digitala resurser som är länkade med varandra. Verktyg som femstjärnig modell för länkad data kan bidra med att visa vilka steg som behöver göras. Modellen är inte ett praktiskt verktyg, utan fungerar som motivation och indikation på nivå av mognad för implementering av länkad data. Det är först vid steg fyra och fem som arbetet med länkad data börjar generera större värden.
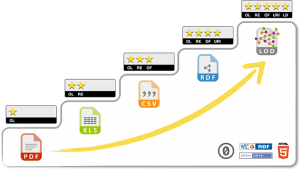 Källa: 5 ★ Open Data
Källa: 5 ★ Open Data
Semantisk webb och begreppsmodeller
Skapande av unika identifierare (URI) för digitala resurser är startskottet för att bygga den semantiska webben och webben 3.0. Detta nya paradigm innebär publicering av data och information i standardiserade format som är avsedda att läsas av maskiner istället personer. Länkad data skapar global interoperabilitet mellan system genom att nyttja av format (RDF, JSON-LD) som länkar ihop viktiga resurser på nätet. Och som blir självförklarande för maskiner genom nyttjande av semantiska modeller som består av taxonomier (RDFS, OWL) och regler för att bygga begrepp- kunskapsmodeller. Modeller brukar innehålla språkanpassningar som gör det möjligt att terminologier och begrepp kan flyttas över landsgränser. När komponenterna för den semantiska webben finns på plats kan artificiell intelligens (AI) och självlärande system bidra till att effektivare och automatisera stora delar av transportsystemet. Bilden nedanför visar vilka format, standarder och protokoll som ligger till grunden för den semantiska webben.
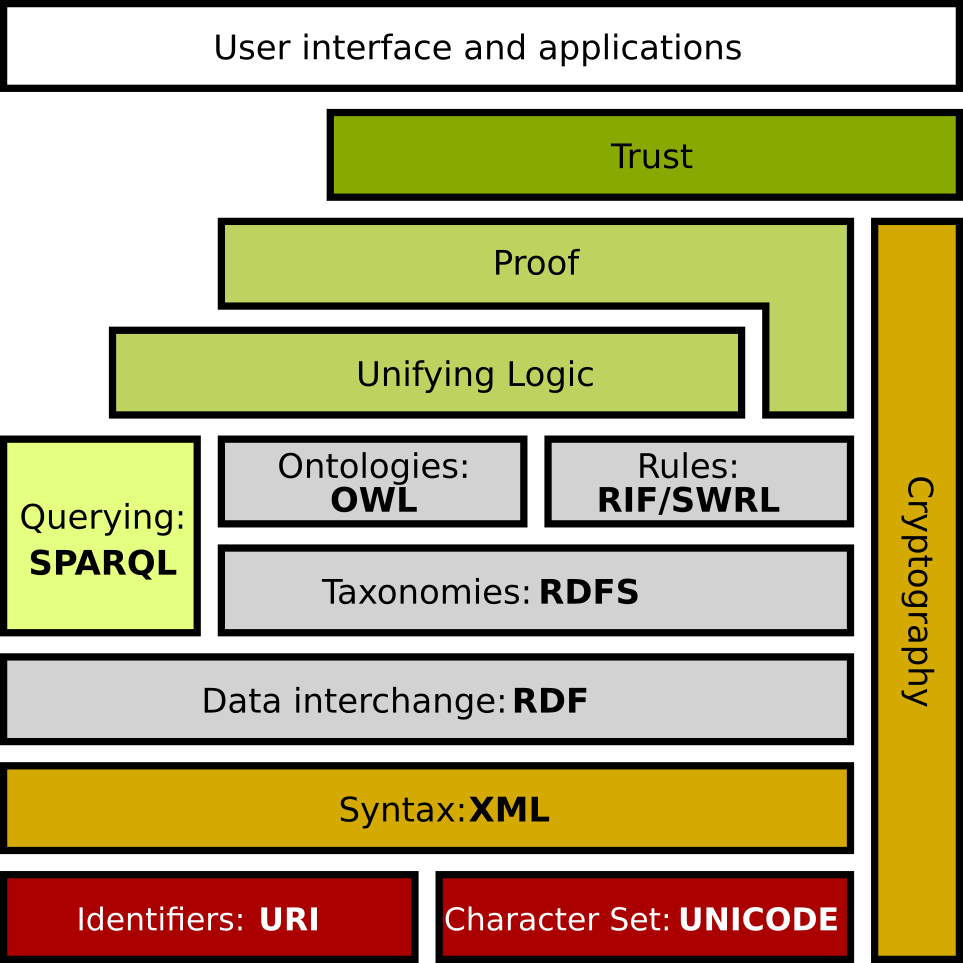
Källa: Wikipedia (en)
SPARQL används för att ställa frågor på digitala resurser som är länkat till en eller flera begreppsmodeller vilket möjliggör interoperabilitet mellan system. Om skoldata och information var publicerad som länkad data och semantisk webb, skulle det gå att ställa frågor om all elevers skolresultat inom EU förutsatt att man nyttjar samma begreppsmodell för att beskriva skolresultat. Exempelvis skulle det vara möjligt att ställa frågor om vilka kommuner, regioner och länder som har elever med medel över betygsnivå B. Om skolresultat var länkat till fakta om elevers demografiska bakgrund, skulle det var möjligt att fråga om föräldrarnas medelinkomsten och vilket område de kommer ifrån.
För att enklare hitta och automatiskt indexera publicerad data finns standarder som DCAT-AP, GeoDCAT-AP som bygger på syntax från formatet RDF som används för länkad data och semantiska webben. DCAT-AP kan också använda för data som inte är sammanlänkad (XLS, CVS, PDF), men då går meningen förlorad med att skapa interoperabilitet mellan system och tillgängliggjorda digitala resurser. EU kommissionens finansierar flera stora program (ISA) inom Europa för att skapa interoperabilitet mellan system och automatisera administration.
Semantiska modeller gör det möjligt att definiera data med bibehållen betydelse över organisation och landsgränser, samtidigt som det minimerar möjligheterna till feltolkning. Modeller kan också länkas med varandra för att utgöra en större helhet. Detta är användbart för att definiera terminologier och begrepp för större verksamhetsområden. Flera branscher använder semantiska modeller idag för att beskriva komplexa förhållande och relationer mellan objekt. Exempelvis finns det modeller för medicinskt terminologi som beskriver kliniska behandlingar av sjukdomar, diagnostik och läkemedel som kallas SNOMED CT(Socialstyrelsen). Projektet är ett internationellt samarbete som har ett antal lokala anpassningar för olika språk som alla länkar tillbaka till en övergripande begreppsmodell. Detta medför att behandling och diagnostik av patienter som flyttas över landgränser blir entydig och minimerar risken för felbehandling beroende på tolkningsfel. En del av arbetet med att modellera semantiska modeller utgörs av att kategorisera och definiera relationen mellan begrepp. Bilden nedan representerar ett exempel av en enkel topologi av relationer mellan några däggdjur och egenskaper de besitter.
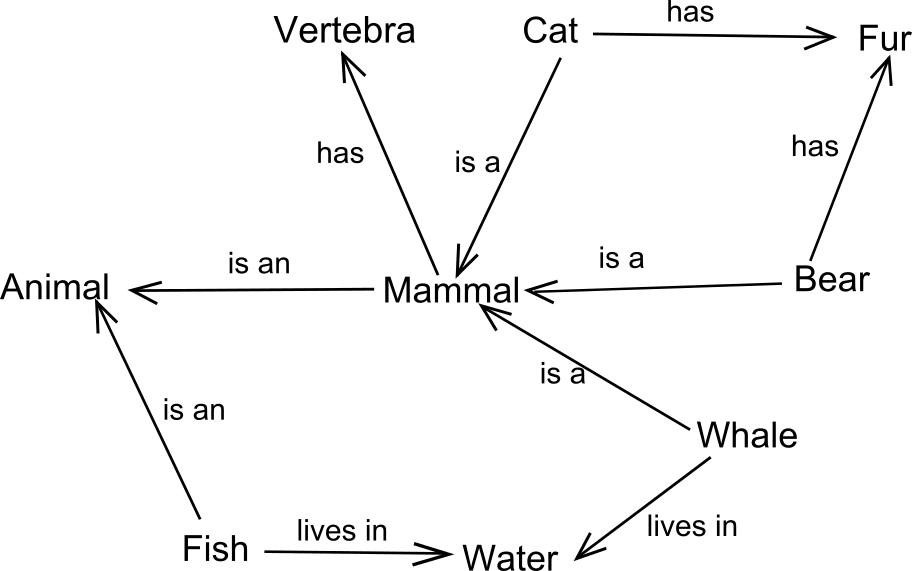
Källa: Semantic network – Wikipedia
Implementering av länkad data
Att styra över fokus från att publicera webbsidor till att publicera länkad data på webben kommer vara en process som behöver tid, kunskap och förståelse eftersom det troligen behövs förändringar av både verksamhetsprocesser och IT-arkitektur. W3C rekommenderar att man börjar med digitala resurser som har stort samhällsvärde och geografisk positioner som kan länkas samman med exempelvis postkoder, kommun och regions indelningar på nationell nivå. Detta eftersom det potentiella samhällsvärdet det skulle kunna skapa i relation till kostnader för att underhålla och skapa semantiska modeller. W3C ger förslag på hur semantiska modeller kan skapas och utvecklas iterativt genom att tillämpa en livscykelprocesser. Förslag nedanför visar på en iterativ process som består av; 1) specificera 2) modellera 3) generera 4) publicera och 5) exploatera.
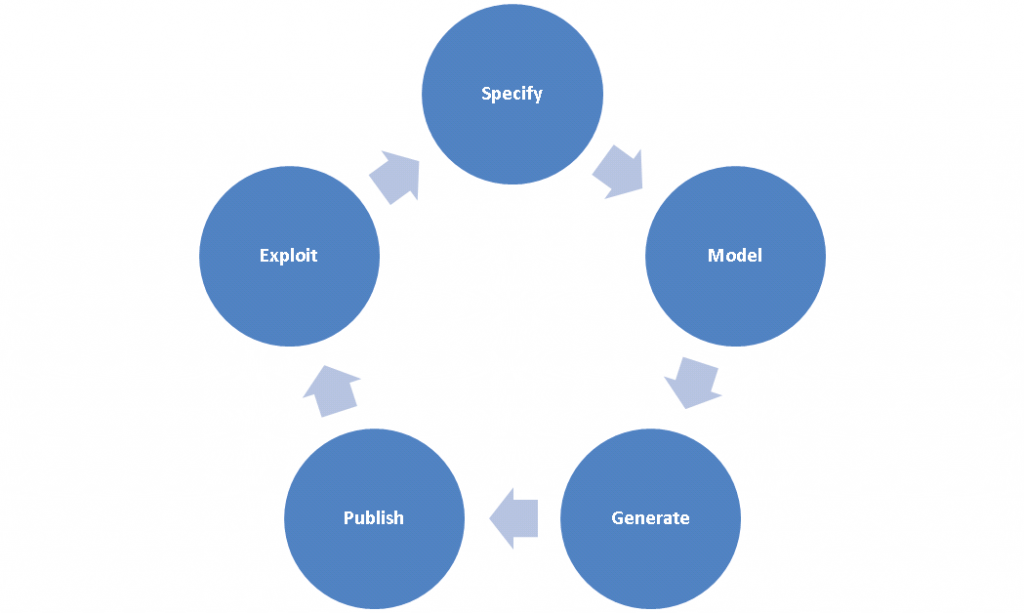
Källa: Best Practices for Publishing Linked Data
Sammanfattning
För att myndigheter och offentliga organisationer skall lyckas med den digitala transformeringen och maximera nyttan som teknologin erbjuder behövs en kontinuerlig inhämtning av kunskap och kompetens av ledare och ansvariga. Om inte goda designprinciper och praxis utnyttjas inom offentlig verksamhet kommer det digitala kunskapsgapet att leda till att offentliga medel kommer berika privata företag som vill upprätthålla leverantörsberoende. Det digitala kunskapsgapet exemplifieras i dag av att fåtal privata leverantörer idag äger stora globala digitala plattformar som låser in privatpersoners data för egen vinning.
Senast uppdaterad 2021-11-26
hmm vad menar vi med det här, varför är det viktigt att använda öppen källkod? och till vad? Det stod samma sak i en rapport från IIS
Därför är det viktigt att öppna data bygger på öppen källkod, teknologier och standarder som kan skapa interoperabilitet mellan system och användare.
Nu har jag inte hunnit läsa IIS rapporten om öppna data ännu. Men om exempelvis öppna data infrastrukturen drivs av en proprietär lösning, som är helt i kontroll av en exempelvis ett vinstdrivande företag. Kan företag välja att låsa in användarna och styra dom att använda andra standarder och produkter som företaget utvecklat. Ta exempelvis Microsoft som inte följde standardisering av HTML och gjorde en egen version för att det passade bättre till deras webbserver och webbläsare. Med avsikt att troligen låsa in användare i till deras ekosystem produkter. Apple är ett annat exempel.
Förenklat kan man säga att även om Microsoft och Apple väljer att följa en öppen standard, finns det riska att dom utvecklar egna tillägg till standaren som bara fungera i deras proprietär system. Eftersom som de är så stora och har så många användare kan de locka över företag och organisationer att köra deras webbserver istället för Apache webbserver (öppen källkod) som följer öppna standarder. Sen när de stora drakarna har alla användare kan de själva utöva påtryckningar av öppna standarder eller hota med att hoppa av arbetet om de inte får som dom vill.
Styrkan med öppen källkod är att det bygger på principen om delaktighet, att alla som deltar ha möjlig att säga sitt om utvecklingen så det inte bara en enskilt förtaga som styr. Vet inte om det var svar på frågan?
vi har ju ett parallellt FOI på G som hanterar frågan ”värdet på information” kanske skulle vara bra att peka på det projektet också och kanske sno nått bra
Jag, vem var det som arbetade med det. Det var ett FOI om jag kommer ihåg rätt?
Kolla med Gustaf Juell-Skielse på Viktoria – tror det är han som projektleder det!