 Öppna data är på väg in i ett nytt paradigm där fokus ligger på användarnas efterfrågan av data i maskinläsbara format, standarder och med öppna licenser som gör den funktionell för sitt tillämpningsområde. På engelska brukar detta benämnas ”liquid information” eller ”liquid data” som går att läsa om i McKinsey’s rapport från 2013. Rapporten visar på vilka potentiella värden som kan uppnås om standarder, format och metadata är funktionella för det avsedda användningsområdet. Ett annat nära besläktat uttryck som förekommer är ”open data 2.0” vilket handlar om att öppna data ska tillgängliggöras utifrån efterfrågan och erbjuda delaktighet där användarna lätt kan rapportera in avvikelser och lämna förbättringsförslag.
Öppna data är på väg in i ett nytt paradigm där fokus ligger på användarnas efterfrågan av data i maskinläsbara format, standarder och med öppna licenser som gör den funktionell för sitt tillämpningsområde. På engelska brukar detta benämnas ”liquid information” eller ”liquid data” som går att läsa om i McKinsey’s rapport från 2013. Rapporten visar på vilka potentiella värden som kan uppnås om standarder, format och metadata är funktionella för det avsedda användningsområdet. Ett annat nära besläktat uttryck som förekommer är ”open data 2.0” vilket handlar om att öppna data ska tillgängliggöras utifrån efterfrågan och erbjuda delaktighet där användarna lätt kan rapportera in avvikelser och lämna förbättringsförslag.

När fenomenet öppen data kom upp på agendan i mitten av 20000-talet fanns en idé om att all data var värdefull bara den var öppen och tillgänglig. Mycket av den data som då publicerades var intern data som gjordes tillgänglig i sitt ursprungliga format som oftast inte var anpassat efter internationella standarder. Till exempel publicerades PDF-filer, inskannade dokument, data i kalkylark, sammanfattade rapporter med bristande underlag med mera. Ur ett innovationsperspektiv visade sig denna data inte vara särskilt värdefull, eftersom den är svår att tillämpa och kombinera med annan data – den är med andra ord non-liquid. Problemet har delvis att göra med att data från interna IT-system innehåller attribut kopplade till den egna verksamheten, som inte lätt låter sig översättas eller förstås av personer utanför organisationen. För att göra data användbar krävs ofta att den harmoniseras och tillgängliggörs i gångbara standarder, format och med tillhörande metadata som förklarar dess egenskaper. Att harmonisera intern data för externt bruk är oftast förenligt med kostnader för att göra den användbar för andra system. Om inte dataägaren tar dessa kostnader, förskjuts dessa i praktiken till användaren som själv måste anpassa data till maskinläsbara format och standarder.
”Många av dataseten på Öppnadata.se använder dataformat som inte främjar maskinläsbarhet, enligt rapport från European Data Portal är endast 26 procent av dataseten maskinläsbara.” – Artikel från 9 Dec 2016

Med ändamålsenlig och öppna data 2.0 (liquid data) avses maskinläsbar data i internationellt gångbara format, standarder och med tillhörande metadata, vilket möjliggör att data kan nyttjas av andra IT-system och kombineras med annan data. Ett exempel på område där data tidigt gjordes ändamålsenlig var inom geografiska informations system (GIS), där inblandande aktörer insåg den strategiska betydelsen av att samverka nationellt och internationellt för att möjliggöra återanvändning av data.
I den bästa av världar nyttjade alla IT-system öppna dataformat, standarder och inkluderade en detaljerad metadatabeskrivning, vilken skulle göra data mer tillgänglig för externa såväl som interna användare. Men att skapa ett IT-stödsystem är oftast mer invecklat och rörigt i verkligheten, eftersom det handlar om en kontinuerlig utveckling och anpassning till en verksamhet över en längre tid, vilket ofta leder till en fragmenterad systemlösning. Mycket tyder på att strategin att bara öppna upp data utan tanke på tillämpningsområde, extern efterfrågan och interaktion med användare, inte leder till eftersökta resultat. För att uppnå bättre effekt, behövs också delaktighet och samverkan komma tillstånd för att göra öppen data mer användbart.
Flera forskningsartiklar har börjat belysa att principer om delaktighet och samverkan behöver adresseras för att göra öppen data användbart. Genom att göra en avvägning och prioritera mellan olika värdedimensioner beroende på tillämpningsområde och vilken användargrupp man riktar sig till. Thorhildur Hansdottir Jetzek definierar i sin doktorsavhandling ”The sustainable value of open goverment data” (2015) liquid open data som gratis, tillgänglig online via öppna licenser, publicerad i maskinläsbara format, lätt att härleda, lättåtkomlig, enhetlig och sammanhållen. Liquid open data kan återanvändas utan begränsningar och med fri tillgång, kunna kombineras med annan data och nyttjas över systemgränser.
Tabellen (Jetzek, 2015, p.45) från avhandlingen belyser sju dimensioner av liquid open data som påverkar möjligheterna att göra data ändamålsenligt. Vilket baserar sig på att dataägare med begränsade resurser, behöver göra en avvägning och prioritering mellan dimensionerna för data skall komma till användning.
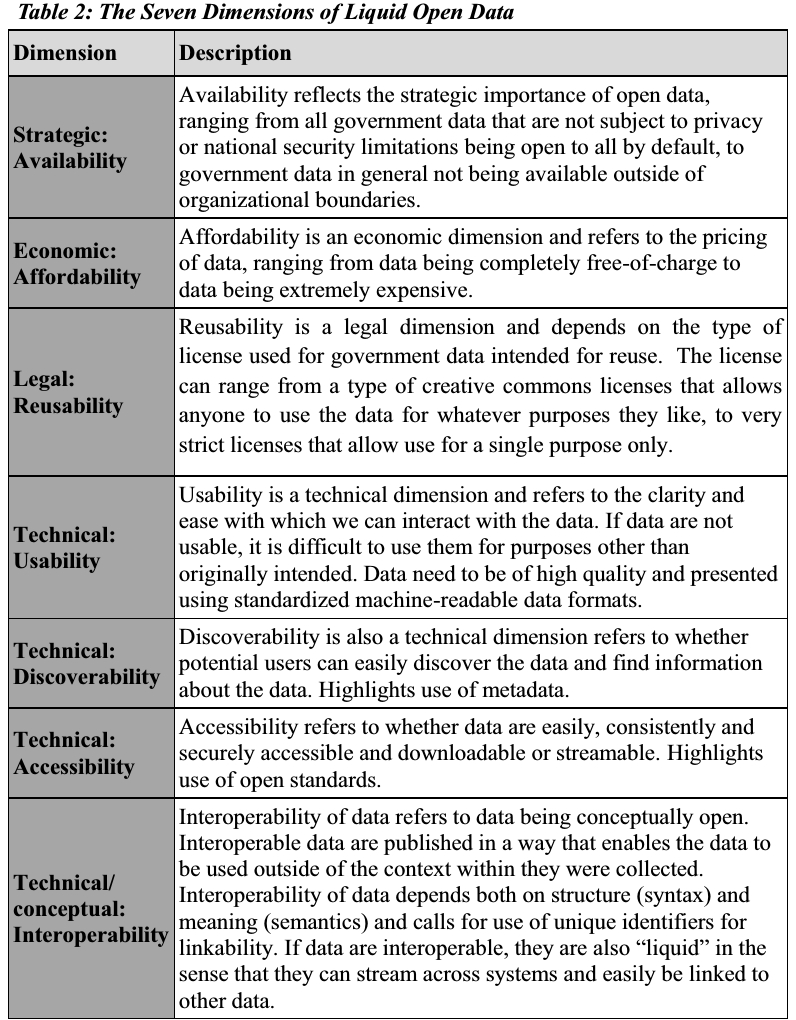
Källa: The Sustainable Value of Open Government Data – Thorhildur Hansdottir Jetzek 2015